
Everyone’s Building Trust Frameworks. Nobody’s Reading the Research.
What DeepMind, the WEF, and Mastercard get right about agent trust — and the fifty years of research they’re ignoring

Abstract: In early 2026, some of the most powerful institutions in the world converged on the same question: how do you trust an AI agent? DeepMind published a moral competence roadmap in Nature. The World Economic Forum proposed “Know Your Agent.” Mastercard launched Verifiable Intent with Google. Microsoft shipped Agent 365. Each of these frameworks contains genuine insight. Each of them also starts from scratch — as if the question “how do humans form trust?” hasn’t been studied rigorously for over fifty years. This article examines what the current wave of trust frameworks gets right, what they miss, and why the gap between industry practice and existing research matters more than either side seems to realise.
In February 2026, Google DeepMind published a Perspective in Nature titled “A roadmap for evaluating moral competence in large language models” [1]. The paper makes a distinction that matters: between moral performance — producing outputs that look appropriate — and moral competence — producing them for the right reasons. The authors identify what they call the facsimile problem: models can imitate moral reasoning without anything resembling genuine understanding. MIT Technology Review captured it in a headline: “Google DeepMind wants to know if chatbots are just virtue signaling” [2].
The same month, a separate DeepMind team proposed an “intelligent delegation” framework for multi-agent systems [3]. Their argument: as agents begin delegating tasks to other agents, formal systems for authority, accountability, and verification become necessary to prevent systemic risk. The framework introduces dynamic capability assessment, reputation mechanisms, and trust calibration. Low-trust agents face stricter constraints and more intensive oversight.

They weren’t alone. In January, the World Economic Forum published “Know Your Agent” [4], drawing a parallel to the Know Your Customer framework that emerged from 1970s financial globalisation. The proposal rests on four capabilities: establishing who and what the agent is, confirming what it’s permitted to do, maintaining clear accountability for every action, and ensuring auditability. A second WEF piece went further, arguing that “trust becomes a core design choice” and proposing a layered trust stack built on legible reasoning, bounded agency, goal transparency, and contestability [5].
Then Mastercard, collaborating with Google, launched Verifiable Intent [6] — a cryptographic proof-of-authorisation layer for agentic commerce. When an AI agent spends real money on your behalf, the consumer needs more than a promise. They need proof that instructions were followed. “Trust becomes the product,” as Mastercard’s Chief Digital Officer put it.
Microsoft shipped Agent 365 [7] — an enterprise governance control plane for monitoring, securing, and governing AI agents at organisational scale. Fast Company declared trust the most important AI benchmark of 2026 [8].
Everyone arrived at the same question at the same time. And every one of them is building the answer from first principles, as if the question is new.
It isn’t.
What they get right
These aren’t bad frameworks. They deserve credit for what they see clearly.
DeepMind’s performance-versus-competence distinction is genuinely important. A model that produces ethical-looking outputs through statistical mimicry is fundamentally different from one that engages with the moral structure of a problem. The facsimile problem is real, and naming it precisely is valuable. Their delegation framework is equally sharp — the insight that multi-agent chains require transitive accountability, where Agent B must verify C’s work before returning results to A, reflects serious thinking about how trust propagates through systems.
The WEF’s distinction between cognitive resonance and emotional persuasion may be the most underappreciated insight in the current wave. Trust built through emotional mirroring — where an agent performs empathy to generate attachment — is fragile. Trust built through systems that behave in ways humans can intuitively understand, anticipate, and critically assess is durable. That’s a real contribution to how we think about agent design.
Mastercard’s Verifiable Intent solves a concrete problem that the more theoretical frameworks don’t touch: when agents transact with real money, you need cryptographic proof, not philosophical frameworks. The engineering is sound.
So the foundations are there. The question is what’s missing.
The Intentionality Gap
The most significant oversight in these 2026 frameworks is the conflation of Global Alignment with Contextual Willingness. Most current safety efforts—like RLHF or Microsoft’s governance plane—focus on making a model “safe” in the aggregate. But trust is not a global average; it is a dyadic belief that the agent will prioritize your specific interest in a given moment.
When Mastercard or Microsoft talk about “verifiable intent,” they are actually describing a Translation Dimension—the gap between what a user says and what an agent executes. They miss the Regulatory Dimension: the “Asimovian” layer where an agent’s willingness is bounded by societal priorities that may override a user’s direct command. By ignoring these layers, industry treats willingness as a hidden, binary assumption rather than a tunable design parameter.
The first miss: the belief structure
Every framework listed above treats trust as a property of the system. Is the agent transparent? Is it bounded? Is it auditable? Does it follow instructions? These are questions about the trustee — the agent being evaluated.
But trust isn’t a property of the trustee. Trust is a property of the trustor’s belief structure — the human (or agent) deciding whether to depend on another party.
This distinction was formalised over two decades ago by Cristiano Castelfranchi and Rino Falcone in what became the Socio-Cognitive Model of Trust [9]. Their framework decomposes trust into three core belief components:
Opportunity — the belief that the trustee has the practical ability to perform the action at a given time and place. Not capability in the abstract, but capability in context.
Ability — the belief that the trustee possesses the competence required to perform the action. This is domain-specific: you might trust someone to drive but not to perform surgery.
Willingness — the belief that the trustee intends to act in the trustor’s interest. Not that they can, but that they will.
These three components are multiplicative, not additive. High ability with zero willingness produces zero trust. High willingness with no opportunity produces zero trust. The structure matters.
Now look at the current frameworks through this lens. DeepMind’s delegation framework reinvents capability matching — that’s ability. Their permission controls map onto opportunity. But willingness is absent. There is no mechanism in the framework for modelling whether the delegated agent intends to act in the delegator’s interest, as opposed to merely executing within its permission boundaries.
The current industry frameworks treat 'willingness'—the belief that an agent intends to act in the user’s interest—as a binary state: an agent is either aligned or it isn't. However, through the lens of the Substitution Coefficient ($\alpha_{sub}$), willingness reveals itself as a multi-dimensional design space. First, there is the Design Dimension: the explicit choice of how closely an agent’s 'fidelity to instruction' is permitted to track a user’s prompt versus its own internal optimization. Second, there is the Translation Dimension: the semantic gap where an agent’s ability to interpret intent creates a hidden barrier to perceived willingness. Finally, there is the Regulatory Dimension: a necessary 'Asimovian' layer where willingness is bounded by societal priorities that may override individual user requests. By treating willingness as a participating parameter rather than a hidden assumption, we can move from reactive alignment to a proactive Weight Matrix ($W$) that optimizes for social capital outcomes rather than just task completion.
The WEF’s trust stack has legible reasoning, bounded agency, goal transparency. These map onto ability and opportunity. Willingness appears obliquely in “goal transparency” — the idea that an agent’s objectives should be explicit — but the framework doesn’t model the trustor’s belief about those objectives, only the system’s declaration of them. Declaring your goals and being believed are different things.
Mastercard’s Verifiable Intent is the closest to capturing willingness — it proves that an agent followed authorised instructions. But it verifies compliance, not intention. An agent can comply perfectly while optimising for objectives that diverge from the consumer’s interest, as long as those objectives don’t violate the letter of the authorisation.
DeepMind’s moral competence paper comes nearest to the full picture. Their performance-versus-competence distinction parallels the CF-T insight that behavioural trust signals (what the agent does) are not the same as the underlying belief structure (what the trustor believes about why). But the paper frames this as a measurement problem — how do we evaluate models? — rather than as a design problem. Which leads to the second miss.
The second miss: reactive measurement versus proactive design
Every framework in the current wave is reactive. They ask: given an agent that already exists, how do we evaluate whether it’s trustworthy? They focus on measuring moral competence, verifying intent, or governing behavior after the fact.
None of them ask the inverse question: given a desired societal outcome, how do we design the agent to produce it?
This is not a subtle distinction. It is the difference between quality assurance and engineering. Quality assurance tells you whether the bridge will hold; engineering tells you how to build it so that it does. By treating trust as a post-hoc “safety” check, we are essentially building bridges and then waiting to see if they collapse before adjusting the blueprint.
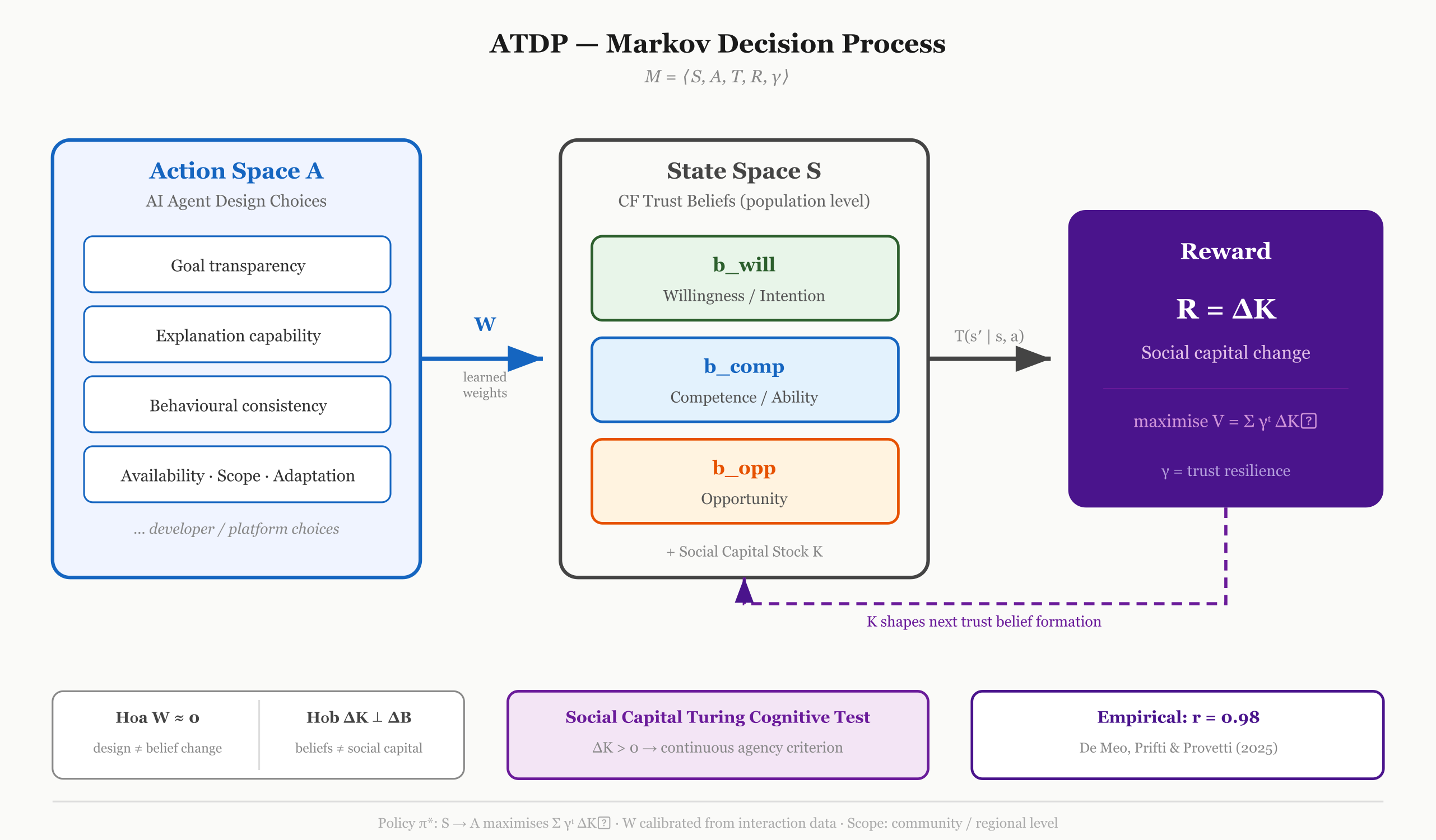
In earlier work, I proposed a framework—Agentic Trust Design for Positive Social Capital (ATDP) [12] — that inverts this direction. Instead of building an agent and then asking “is it trustworthy?”, we treat agent design as a deliberate decision variable within a formal system.
The framework is built as a Markov Decision Process (MDP) where the reward function is defined as Delta K: the change in aggregate social capital. Within this model:
States (S) capture population-level trust belief distributions—specifically competence, willingness, and opportunity—using the Castelfranchi-Falcone components.
Actions (A) represent specific agent design properties—the transparency, consistency, and constraints we choose to build.
The Weight Matrix (W) maps these design choices to changes in human trust beliefs, allowing us to calculate the influence of a feature before it is deployed.
The implication is structural. It allows us to start with the social outcome we want—increased social capital, maintained trust equilibria, or avoided erosion—and work backward through the framework to determine which design properties will produce that outcome.
DeepMind’s moral competence roadmap proposes better tests; the ATDP framework proposes better blueprints. Both are necessary, but the current discourse is almost entirely on the testing side. Without a proactive, outcome-driven design model, we aren’t actually “engineering” trust—we are just auditing its absence.
The third miss: the two dimensions of substitution
When an AI agent acts on behalf of a human—booking travel, making a purchase, or selecting a childcare provider—it substitutes for the human along a specific dimension of the interaction. The current frameworks treat this substitution as a single, binary toggle: either the agent does the task, or it doesn’t.
In the ATDP framework, we identify that this substitution (alpha_sub) actually consists of two independent dimensions that the industry currently conflates:
The Technological Ceiling: What the model is actually capable of doing based on its architecture and inference power. This is an engineering fact that moves with the state of the art.
The Design Ceiling: What we deliberately allow the agent to do based on policy and intentional constraint. This is a human decision.
The “blind spot” in the WEF and Microsoft frameworks is the assumption that we should always push the design ceiling as close to the technological ceiling as possible. But the ATDP framework predicts a Composition Threshold: there is a point where maximizing substitution erodes community-level social capital, even if the individual interaction is “successful”.
By conflating these two ceilings, we lose the vocabulary to say: “The agent is capable of full autonomy, but we are capping it at recommendation-only to preserve the social capital of the human network”. No current industry framework provides the language to make that distinction operational.
Why the gap matters
This isn’t an academic complaint. The gap between what’s being built and what’s already known has practical consequences.
Without the belief structure, trust frameworks optimise for the wrong target. They make agents more transparent, more auditable, more bounded — all good things — without modelling whether those properties actually change what the trustor believes. You can build the most transparent agent in the world and still fail to generate trust if the user doesn’t believe the agent is willing to act in their interest. Transparency is necessary but not sufficient, and the CF-T framework explains precisely why.
Without the proactive design inversion, we’re stuck in a cycle of build-then-evaluate. Every new agent capability triggers a new round of governance frameworks, trust assessments, and safety evaluations. The ATDP approach offers a path out: design for the outcome from the start, rather than retrofitting trust after deployment.
Without the two-dimensional substitution model, governance conversations conflate “what AI can do” with “what AI should be allowed to do.” These are different questions with different stakeholders, different timescales, and different accountability structures. The current frameworks don’t give us the language to separate them.
Conclusion: The Social Capital Turing Cognitive Test
The convergence of DeepMind, the WEF, and Microsoft on the problem of trust is an encouraging signal that AI has moved from a playground to a social infrastructure. But as we have seen, institutional weight is not a substitute for theoretical depth. By ignoring fifty years of socio-cognitive research, the current wave of frameworks risks building “trustworthy” agents that fail to actually generate trust.
We need a more rigorous benchmark. In the ATDP framework, I propose moving beyond the classical Turing Test—which is binary, based on deception, and ultimately subjective—toward a Social Capital Turing Cognitive Test.
This new test asks a simple, quantifiable question: Does the introduction of this AI agent into a network result in a measurable increase in the aggregate social capital of that network?
Unlike the 1950s version, this test is:
Continuous: It is measured by the change in social capital (Delta K), admitting degrees of agency rather than a simple pass/fail.
Non-Deceptive: It doesn’t require the agent to “fool” a human; it only requires the agent to function as a reliable node in a trust exchange.
Consequentialist: It evaluates the agent by its actual societal effects—grounded in economic data—rather than its internal processes or “virtue signaling”.
If an AI agent can negotiate, transact, and mediate in a way that produces the same measurable economic and social outcomes as human-to-human interactions, it has achieved a form of functional cognitive agency that matters more than any benchmark score.
The tools to build this bridge already exist in the work of Castelfranchi, Falcone, and Putnam. It is time the industry stopped reinventing the wheel and started using the blueprints we already have.
Ylli Prifti, Ph.D., writes about AI, cognition, and engineering culture on Weighted Thoughts.
References
[1] Haas, J., Isaac, W., et al. “A roadmap for evaluating moral competence in large language models.” Nature, February 2026. https://www.nature.com/articles/s41586-025-10021-1
[2] “Google DeepMind wants to know if chatbots are just virtue signaling.” MIT Technology Review, February 2026. https://www.technologyreview.com/2026/02/18/1133299/google-deepmind-wants-to-know-if-chatbots-are-just-virtue-signaling/
[3] Google DeepMind. “Intelligent Delegation: A Framework for the Agentic Web.” arXiv preprint, February 2026.
[4] “AI agents could be worth $236 billion by 2034 — if we ensure they are the good kind.” World Economic Forum, January 2026. https://www.weforum.org/stories/2026/01/ai-agents-trust/
[5] “How to design for trust in the age of AI agents.” World Economic Forum, February 2026. https://www.weforum.org/stories/2026/02/how-to-design-for-trust-in-the-age-of-ai-agents/
[6] “Verifiable Intent.” Mastercard, March 2026. https://www.mastercard.com/us/en/news-and-trends/stories/2026/verifiable-intent.html
[7] “Secure agentic AI for your Frontier Transformation.” Microsoft Security Blog, March 2026. https://www.microsoft.com/en-us/security/blog/2026/03/09/secure-agentic-ai-for-your-frontier-transformation/
[8] “AI’s most important benchmark in 2026? Trust.” Fast Company, December 2025. https://www.fastcompany.com/91462096/ai-trust-benchmark-2026-openai-anthropic
[9] Castelfranchi, C. & Falcone, R. “Trust Theory: A Socio-Cognitive and Computational Model.” Wiley Series in Agent Technology, 2010. https://doi.org/10.1002/9780470519851
[10] Prifti, Y. “Social Capital Is a Design Choice.” Weighted Thoughts, March 2026. https://weightedthoughts.substack.com/
[11] De Meo, P., Prifti, Y., & Provetti, A. “Trust Models Go to the Web: Learning How to Trust Strangers.” ACM Transactions on the Web, Volume 19, Issue 2, March 2025. https://doi.org/10.1145/3715882
[12] Prifti, Y. (2026). Social Capital Is a Design Choice: A Markov Framework for AI Trust and Societal Outcomes. SSRN Preprint ID 6390618. Available at: https://ssrn.com/abstract=6390618