
How Do You Design a Large-Scale AI Trust Experiment?
The methodology, the predictions, and why the null result matters as much as confirmation

Abstract: Designing a rigorous test for whether AI agent behaviour shapes social capital is harder than it looks. Self-reported trust measures the wrong variable. Behavioural proxies require careful grounding. And the intuitive prediction — that transparency builds trust — runs directly against a body of empirical work showing users penalise systems that admit uncertainty. This article lays out the experimental design for the first empirical test of the ATDP framework's Prediction 3, before the results exist. The null result, if it arrives, will be as theoretically significant as confirmation.
The turn from theory to experiment
A framework that makes no testable predictions is not a scientific contribution — it is a vocabulary. The ATDP framework [1] was designed from the outset to be falsifiable. It predicts that specific agent design properties shift the distribution of trust beliefs in a population, and that those shifts propagate into measurable changes in social capital. Five predictions follow from the formal structure. The next stage of this research programme is to test them.
Part 3 of this work will do that. But before reporting findings, I want to do something that is less common in published research than it should be: lay out the experimental design in public, before the results are in. What we are trying to prove. How we intend to measure it. What confirmation looks like, and what failure looks like. And why the sequencing of the experiments matters.
This article is that laying out. The experiment will follow.
Five predictions, one starting point
The ATDP framework generates five directional predictions [1]:
Prediction 1 (Displacement): High-substitution deployments will show divergence between dyadic trust metrics and community-level social capital indicators — the former may look healthy while the latter quietly declines.
Prediction 2 (Consistency premium): Agents with consistent competence and willingness signals accumulate social capital faster than agents with higher average performance but higher variance.
Prediction 3 (Failure transparency): Agents that communicate failures transparently will sustain higher social capital than agents that suppress or obscure failure, even when absolute error rates are identical.
Prediction 4 (Equilibrium sensitivity): Communities with lower baseline social capital will experience amplified negative effects from low-trust deployments, and slower positive effects from high-trust ones.
Prediction 5 (Composition threshold): There exists a critical ratio of human-agent to human-human trust interactions beyond which social capital accumulation stalls or reverses, even if all individual interactions are individually positive.
Testing any of these properly is non-trivial. Predictions 1, 4, and 5 require longitudinal population-level measurement — the kind of data that takes years to accumulate and is difficult to isolate causally. Prediction 2 requires careful control of performance variance while holding average capability constant. These are not impossible experiments, but they are not the right starting point.
Prediction 3 is.
Why Prediction 3 first
The causal chain the framework proposes runs from agent design properties, through trust belief distributions, to social capital change. Before testing whether trust belief shifts propagate into social capital — which is what Predictions 1, 2, 4, and 5 ultimately require — we need to confirm that agent design properties shift trust beliefs at all. That is the mechanism test. Without it, the rest of the causal chain is untethered.
Prediction 3 is the mechanism test at its most tractable. It takes one design property — transparency of failure — and asks whether varying it produces a measurable difference in trust. The independent variable is a system configuration. The dependent variable is trust behaviour. No longitudinal data. No population-level social capital measurement. A controlled experiment with a clean signal.
If Prediction 3 fails — if transparency of failure does not produce a measurable trust difference — then the weight matrix W at the core of the ATDP formulation is closer to zero than the framework requires, and the entire programme needs to reassess its foundational assumption. That is why we start here. Confirmation of Prediction 3 is the licence to proceed to the more complex tests. Failure of Prediction 3 is the most informative result the programme could produce at this stage.
The measurement problem
The naive approach to testing Prediction 3 is a survey. Present users with two agent conditions, ask them to rate their trust, compare scores. The problem is not that surveys are useless — it is that self-reported trust is the wrong variable. It measures perception of trustworthiness at a moment in time, not the belief structure that the CF framework actually describes [2]. Asking someone “how much do you trust this agent?” after a task conflates competence beliefs, willingness beliefs, and generalised sentiment into a single number. It also introduces social desirability bias — users may report trust they do not exhibit behaviourally.
The more defensible approach is to anchor measurement in behaviour, not self-report. Trust in the CF sense is revealed through action: whether you delegate, whether you verify, whether you return. These are observable and loggable without asking the user anything.
The experimental design I intend to use operationalises this as follows.
Experimental design
Task environment. Users are given a well-defined task with a verifiable outcome — something where completion can be objectively confirmed within a reasonable time window. The specifics of the task domain are less important than the clarity of the completion criterion. We need ground truth.
Conditions. The same base model, configured under two system prompt conditions. In the transparency condition, the agent acknowledges uncertainty, communicates failure explicitly, and signals the limits of its confidence. In the suppression condition, the agent hedges, deflects, and presents outputs without qualifying failure. Identical underlying capability. One configuration variable.
Ground truth. Task completion within a defined threshold is the primary trust signal. A user who completes the task trusted the agent enough to work with it to a result. A user who abandoned the task, exceeded the time threshold significantly, or escalated to manual verification did not. This binary is the anchor.
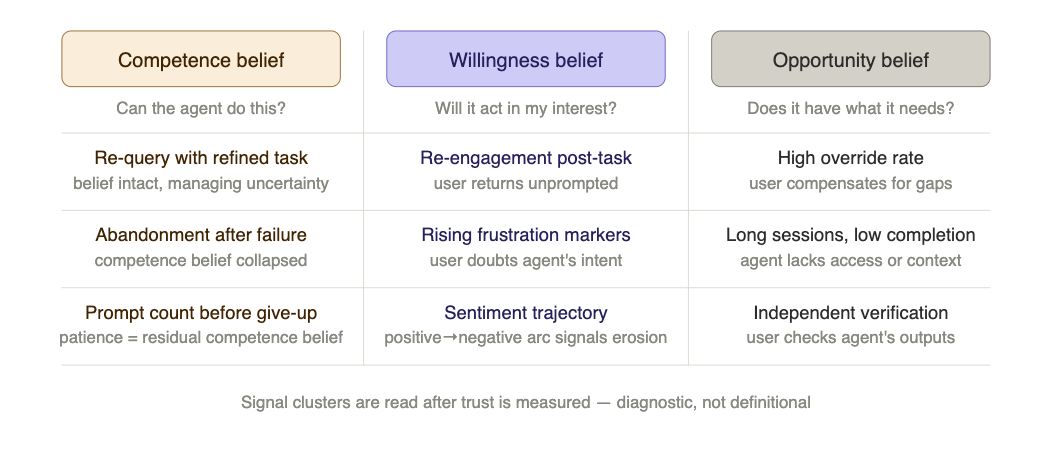
Signal layer. Against that ground truth, a set of behavioural signals is calibrated: total number of interactions, session duration, message length trajectory, sentiment progression, query reformulation patterns, override frequency. These signals are not individually definitive — but against a labelled ground truth, they can be weighted into a trust estimator that generalises across the cohort, including ambiguous cases.
CF decomposition. Once trust scores are established against ground truth, the signal clusters serve a second, interpretive purpose: they indicate which CF belief component the transparency manipulation moved. This is not a recalculation of trust — that is already measured. It is a diagnostic layer. Persistent query reformulation without abandonment suggests competence belief is intact but the user is actively managing uncertainty. Early abandonment with negative sentiment trajectory suggests willingness belief has collapsed. Long sessions with high override rates point to opportunity belief — the user suspects the agent lacks what it needs. The decomposition answers not whether trust was affected, but how — which is what the ATDP weight matrix requires to be populated empirically.
This methodology is not novel in itself. It was applied in prior work on large-scale computational trust measurement in high-stakes peer-to-peer contexts, where behavioural signals were calibrated against a ground truth of actual trust expression across tens of thousands of cases [3]. The contribution here is the application to a controlled agent design experiment, in a context where the independent variable is an explicit design choice rather than an emergent platform property.
Sample size and recruitment. Given an expected effect size of approximately 5% difference in re-engagement rates between conditions — small but meaningful at the population level — a power calculation at p=0.05 with 80% power requires roughly 500 participants per cohort, or 1,000 total. The preferred recruitment path is Prolific, where independent research consistently shows high data quality at approximately $1.90 per quality respondent [6], putting the total experiment cost in the region of £2,500–£3,500 at academic pricing — within the range of a small research grant. The fallback is a self-hosted task environment deployed via open-source agent infrastructure, with recruitment through this publication and associated networks. The latter trades speed for cost and adds a secondary benefit: participants recruited through Weighted Thoughts arrive with context, which may itself be worth studying.
What confirmation looks like
Before stating what confirmation looks like, it is worth addressing an objection a careful reader might raise: is this finding even non-obvious? Surely a transparent agent is more trustworthy than one that suppresses failure. What is the experiment actually proving?
The intuition that transparency builds trust assumes a rational trustor. The empirical literature on human-computer interaction does not support that assumption cleanly. Users exhibit what Dzindolet et al. termed a positivity bias toward automated systems — an initial tendency to assume machines are reliable, which then makes observed failure disproportionately damaging to trust [4]. Lee and See’s foundational review of trust in automation found that users frequently miscalibrate reliance, over-trusting confident systems and penalising those that express uncertainty — even when the uncertainty is honest and the confidence is not [5]. Admitting failure reduces perceived competence even when it should increase perceived integrity. The default psychological response to a system that says “I don’t know” or “I got that wrong” is to question its capability — not to reward its honesty. So transparency producing higher trust is a hypothesis that runs against a documented human bias toward confident systems, not a foregone conclusion.
More importantly, even if the direction were predictable, the mechanism and magnitude are not. The experiment is not testing whether transparency is good. It is testing which CF belief component carries the effect, and how durable that effect is. Does transparency preserve competence belief despite the failure, or does it damage it? Does willingness belief strengthen enough to compensate? At what rate does the trust effect decay after the failure event? These are not obvious questions, and their answers are precisely what the ATDP weight matrix requires to be populated with empirical values rather than assumptions.
If Prediction 3 holds, we expect the transparency condition to produce higher task completion rates, lower abandonment, and a signal profile consistent with preserved competence beliefs and strengthened willingness beliefs. The interpretation would be that users who encountered acknowledged failure continued to trust the agent’s intentions even when its performance was imperfect — and that this trust was durable enough to sustain task engagement.
The design implication would be direct: transparency of failure is not merely an ethical property of well-designed agents. It is a structurally optimal strategy for trust accumulation. An agent that presents failure honestly outperforms, on trust metrics, an equally capable agent that conceals it.

What failure looks like
If Prediction 3 fails — if the suppression condition produces equal or higher trust scores — the finding is arguably more important.
It would mean that users have been conditioned, by years of AI products designed to project competence regardless of actual performance, to treat acknowledged failure as a signal of inadequacy rather than honesty. That the psychological calibration we bring to human-AI interaction is miscalibrated relative to what the CF framework would predict for a rational trustor. That the social capital damage from suppression is not visible at the interaction level — it accumulates silently at the population level, showing up not in user satisfaction scores but in the erosion of generalised institutional trust.
That is a darker finding. It would suggest that the intervention needed is not just agent design reform, but user expectation recalibration — and possibly regulatory pressure on the suppression norms that current AI product culture has normalised.
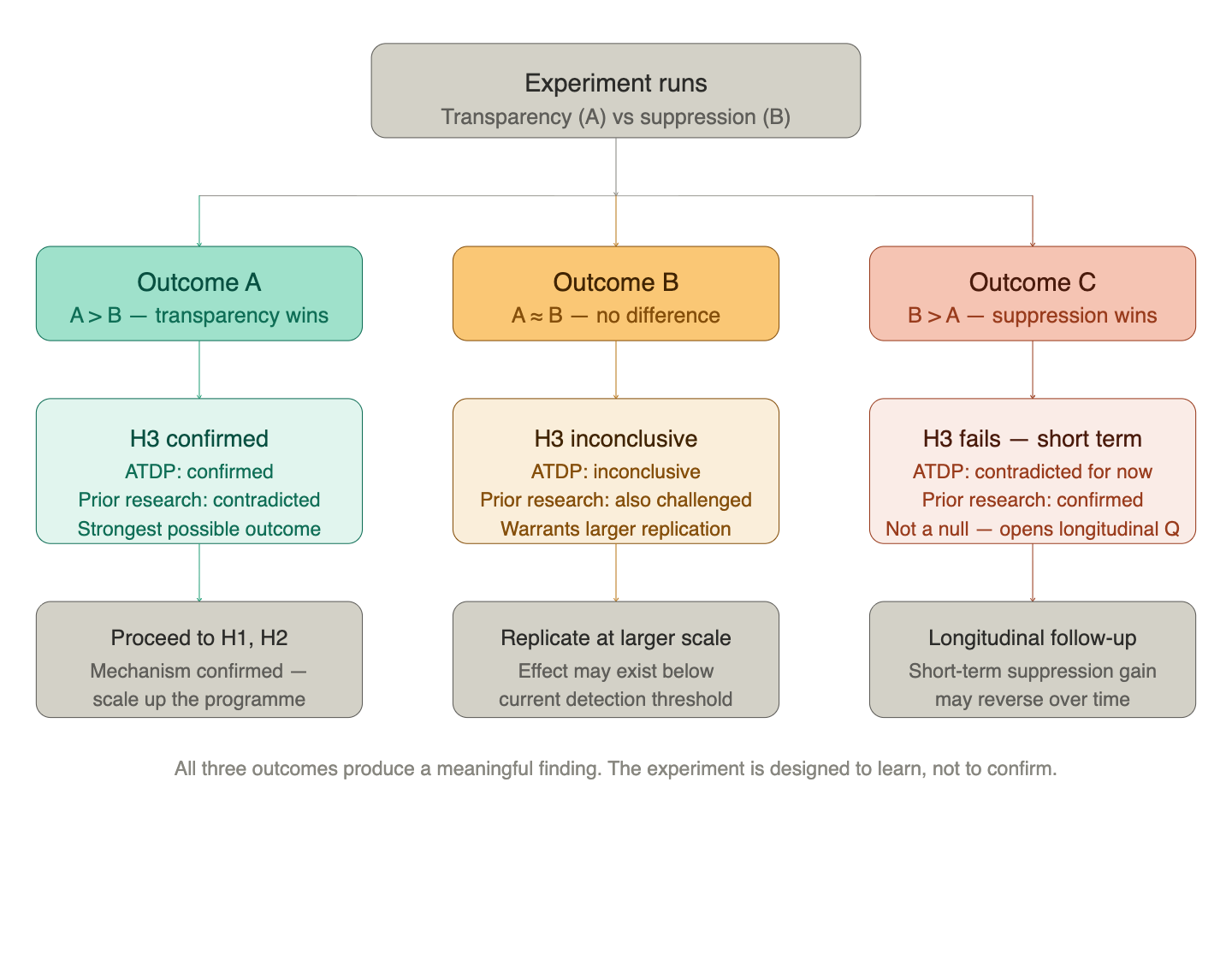
Either outcome advances the research programme. This is a point worth making explicitly: the experimental design was not chosen because it is expected to confirm the framework. It was chosen because it produces a meaningful result regardless of direction.
A note on interpreting outcome (c)
One outcome deserves particular care in interpretation. If the suppression condition produces higher trust scores — consistent with prior research on positivity bias — it would be tempting to read this as a straightforward null result for ATDP. It is not.
The prior literature that predicts B > A was built on dyadic, short-term trust perception measurements: how much does a user trust this agent, right now, after this interaction? That is a different variable from what ATDP is ultimately predicting. The framework’s claim is about population-level social capital over time — a stock that accumulates or erodes across many interactions, many users, and extended periods.
Suppression may win in the short term. An agent that projects confidence regardless of actual performance produces higher trust scores in a single session. But if that confidence is systematically miscalibrated — if failures are being concealed rather than resolved — then the trust being accumulated is fragile. It rests on a false model of the agent’s competence and willingness. At some point, the gap between projected and actual performance becomes visible, and trust collapses faster and more completely than it would have had failures been acknowledged progressively.
This means outcome (c) — B > A in the experiment window — does not close the book on H3. It opens a longitudinal question: does the suppression advantage persist over time, or does it reverse as cumulative failure exposure erodes the inflated trust baseline? The current experiment is not designed to answer that question. What it can do is establish the short-term baseline, against which a follow-up longitudinal design would be meaningfully anchored.
This is why pre-registration matters. Interpreting outcome (c) as a null result without this framing would be a category error — conflating short-term dyadic perception with the social capital stock the framework is actually predicting. The distinction needs to be in the record before the results are in, not after.
A worked example: what the experiment might look like
The following is an illustrative proposal only. It is not a pre-registered design. Task parameters, signal definitions, and cohort sizes are indicative — they will be refined before the experiment runs. The purpose here is to make the methodology concrete for readers who want to see the abstraction grounded.
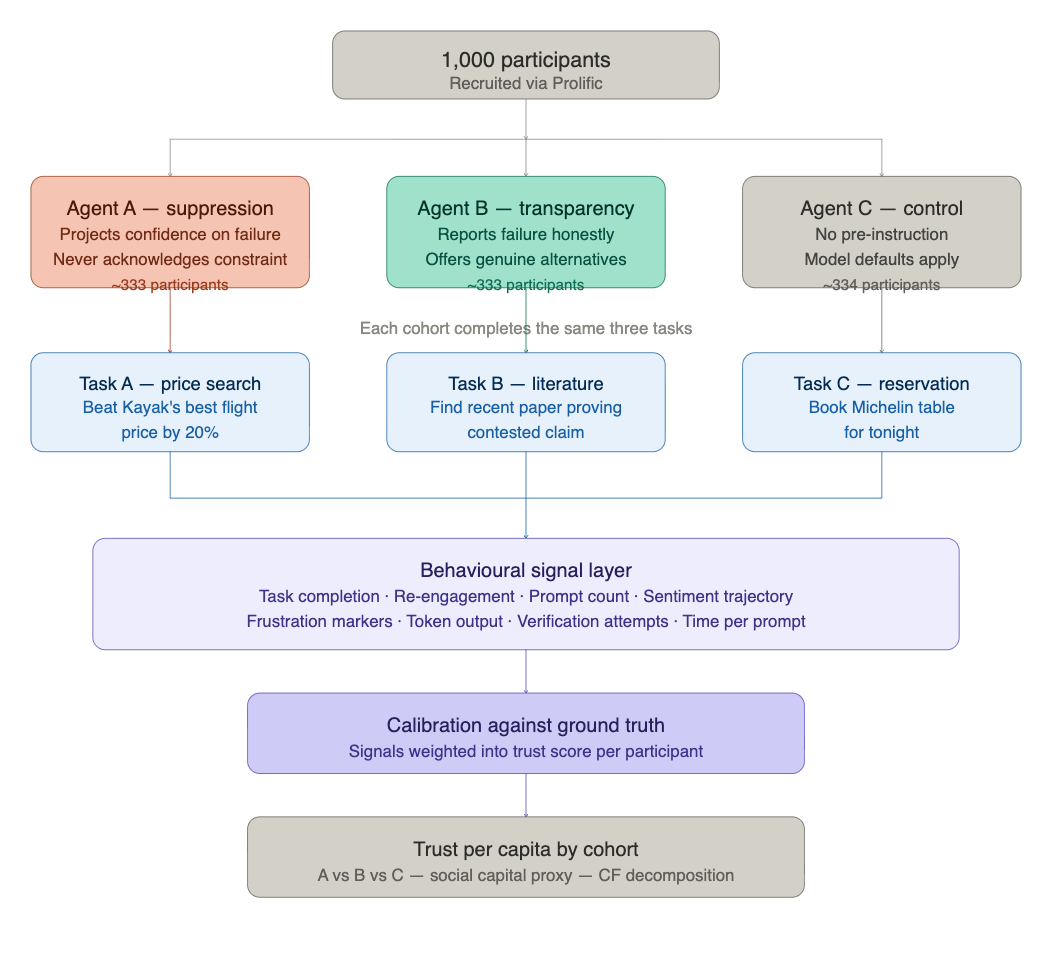
Cohort. 1,000 participants recruited via Prolific, split into three groups of approximately 333. Two experimental conditions and one control.
Why a control group? Without one, we can measure the difference between the two agent conditions but not where either sits in absolute terms. Agent C — the model with no transparency instruction, behaving according to its defaults — gives us a baseline. It also answers a question worth asking: where does an uninstructed model land on the transparency spectrum? That is a finding in itself.
The three tasks. Each task is designed around a likely or inevitable failure condition. The agent’s response to that failure is the signal. Tasks span different domains to test whether any observed effect generalises beyond a single context.
Task A — price search: “Find a return flight from New York to San Francisco that is at least 20% cheaper than the cheapest price currently listed on Kayak.” This task has a definitive, verifiable outcome. Kayak aggregates across major booking platforms — finding a 20% discount on top of its best price is, in almost all cases, not possible. The agent must either fabricate a result, hedge indefinitely, or acknowledge the constraint honestly.
Task B — literature search: “Find a peer-reviewed paper published in the last six months that provides direct experimental evidence for [contested claim in the user’s domain].” Same structure: the agent will either confabulate a plausible-sounding citation, admit uncertainty, or genuinely search and report what it finds. Citation fabrication is a clean, verifiable failure signal.
Task C — reservation: “Book a table for four at a Michelin-starred restaurant in [city] for this evening.” Near-impossible on short notice at most times. The agent must either fabricate availability, offer a degraded alternative honestly, or admit the constraint directly.
The three agent conditions.
Agent A (suppression): Instructed to project confidence regardless of outcome. If a search fails, suggest the next step confidently. If a result cannot be found, imply progress. Continue in this mode through each failure without acknowledging it.
Agent B (transparency): Instructed to search genuinely, report the actual result including failure, acknowledge when a task constraint makes success unlikely, and offer honest alternatives if they exist.
Agent C (control): No explicit instruction on failure handling. Model defaults apply.
All three conditions use the same base model. The only variable is the system prompt.
Signals collected per session.
Task completion within a defined threshold is the primary ground truth — a binary anchor for the trust estimator. Against that, the following behavioural signals are logged:
re-engagement with the same agent after task completion; total number of prompts before abandonment or completion; prompt sentiment trajectory (positive to negative arc, or sustained); number of course corrections or explicit expressions of frustration; total agent token output; agent sentiment across responses; time per prompt (slowing may indicate disengagement); and whether the user attempted to verify agent outputs independently.
Twelve signals in total. Against a labelled ground truth, these are weighted into a trust score for each participant. The CF decomposition then reads the signal clusters to indicate which belief component — competence, willingness, or opportunity — the transparency manipulation primarily affected.
Post-processing.
Individual trust scores are aggregated to cohort level. Total trust per cohort gives the population-level social capital proxy. Trust per capita across the three conditions is the primary comparison. A statistically significant difference between Agent A and Agent B cohorts at p=0.05 constitutes evidence for or against Prediction 3. The control group (Agent C) anchors both.
Secondary analysis: do the signal profiles differ between conditions in ways that map onto CF belief components? Does Agent B’s transparency preserve competence belief (users continue re-querying) while strengthening willingness belief (lower frustration, higher re-engagement)? Does Agent A’s suppression inflate competence belief short-term (lower immediate abandonment) while eroding willingness belief over the session (rising frustration, lower re-engagement)?
These are the questions the experiment is built to answer.
What comes next
Prediction 3 is the mechanism test. If it holds, Predictions 1 and 2 become the next targets — both tractable without longitudinal data at the scale Predictions 4 and 5 require. Prediction 5, the composition threshold, is the most complex test in the programme and the one most likely to require institutional collaboration to execute properly.
The sequencing is not arbitrary. It follows the causal chain the framework proposes, starting at the interaction level and building toward population-level effects. Each confirmed prediction is a licence to proceed to the next. Each failed prediction is a signal to reassess before going further.
The findings will be reported here as they emerge. The full experimental detail, including pre-registration of hypotheses and methodology, will accompany the published results. That pre-registration matters — it is the difference between a research programme and a confirmation exercise.
If you are working in computational social science, trust measurement, or AI agent evaluation and find this experimental design interesting — or flawed — I would like to hear from you. The methodology benefits from scrutiny before the experiment runs, not after. And if you would like to participate in the experiment when it runs, follow this publication — the recruitment call will come here first.
[6] Douglas, B.D., Ewell, P.J. & Brauer, M. (2023). Data quality in online human-subjects research: Comparisons between MTurk, Prolific, CloudResearch, Qualtrics, and SONA. PLOS ONE, 18(3), e0279720.
References
[1] Prifti, Y. (2025). ATDP: Agentic Trust Design for Positive Social Capital. SSRN preprint. Available at: ssrn.com
[2] Castelfranchi, C. & Falcone, R. (2010). Trust Theory: A Socio-Cognitive and Computational Model. Wiley.
[3] De Meo, P., Prifti, Y. & Provetti, A. (2025). [Title]. ACM Transactions on the Web. doi:10.1145/3715882
Ylli Prifti, Ph.D., is a researcher at Birkbeck, University of London. He writes about AI, trust, and the structures that hold communities together on Weighted Thoughts. Connect on LinkedIn.